有一實驗設備的 API 服務無法使用,檢查發現 database 用的磁碟空間為 0,佔用空間的竟然是 pg_wal 資料夾裡的 WAL 檔案。因此需要分析在 PostgreSQL master-slave replication 的架構,master node 的 WAL 檔案為什麼會持續增加,導致磁碟空間不足,讓 database 無法正常服務。
1. 設定模擬環境
基於 Bitnami PostgreSQL Docker Image - bitnami/postgresql-repmgr ,選用的是 PostgreSQL v13 版本,再配合實驗設備進行部份設定值的調整
Host OS 為 Ubuntu 20.04
Disk space 4GB
請同事開二組包含上述條件的 VM 來模擬 PostgreSQL master-slave replication 的架構。
1.1. 查詢參數值 由於 VM 刻意限縮可使用的容量,以儘快模擬出”磁碟空間”不足的情境,所以預設的 WAL 參數也要做對應的調整,可以從 master node 的 database 裡查到參數值。
在模擬環境的 mater node VM 使用 docker exec 指令進入 db container,登入 PostgreSQL,
1 $ PGPASSWORD=ADM_PSQL_PWD psql -U ADM_PSQL_ACCOUNT
查詢 pg_wal 可使用的最大容量,
結果如下,
1 2 3 4 5 max_wal_size -------------- 120MB (1 row)
查詢至少要保留多少容量的 WAL 檔案,
結果如下,
1 2 3 4 wal_keep_size --------------- 48MB (1 row)
離開 PostgreSQL,可用 \q 或 exit。
1.2. 正常運作下的 pg_wal 資料夾 在正常運作的情況下,可以看到 pg_wal 資料夾佔用的空間不會偏離設定值 max_wal_size 太多。
在 db container 內,查看 pg_wal 資料夾,
1 2 3 4 5 6 7 8 9 10 11 12 13 $ ls -lh /bitnami/postgresql/data/pg_wal/ total 129M -rw------- 1 1001 root 333 Mar 24 09:26 000000010000000000000033.00000028.backup -rw------- 1 1001 root 16M Mar 24 10:03 00000001000000000000004A -rw------- 1 1001 root 16M Mar 24 10:05 00000001000000000000004B -rw------- 1 1001 root 16M Mar 24 10:06 00000001000000000000004C -rw------- 1 1001 root 16M Mar 24 10:08 00000001000000000000004D -rw------- 1 1001 root 16M Mar 24 09:56 00000001000000000000004E -rw------- 1 1001 root 16M Mar 24 09:59 00000001000000000000004F -rw------- 1 1001 root 16M Mar 24 10:00 000000010000000000000050 -rw------- 1 1001 root 16M Mar 24 10:02 000000010000000000000051 drwx------ 2 1001 root 4.0K Mar 24 10:08 archive_status
查看磁碟空間的使用情況,
1 2 3 4 5 6 7 8 9 10 $ df -h Filesystem Size Used Avail Use% Mounted on overlay 3.7G 3.4G 295M 93% / tmpfs 64M 0 64M 0% /dev tmpfs 2.0G 0 2.0G 0% /sys/fs/cgroup shm 64M 64K 64M 1% /dev/shm /dev/vda1 3.7G 3.4G 295M 93% /bitnami/postgresql tmpfs 2.0G 0 2.0G 0% /proc/acpi tmpfs 2.0G 0 2.0G 0% /proc/scsi
查看 PostgreSQL 各資料夾使用磁碟的情況,
1 2 3 4 5 6 7 8 9 10 $ du -h -d 1 /bitnami/postgresql/data/ | sort -rh 552M /bitnami/postgresql/data/ 423M /bitnami/postgresql/data/base 129M /bitnami/postgresql/data/pg_wal 584K /bitnami/postgresql/data/global 120K /bitnami/postgresql/data/pg_subtrans 40K /bitnami/postgresql/data/pg_stat_tmp 28K /bitnami/postgresql/data/pg_multixact ...
/bitnami/postgresql/data/base 為 database 的資料夾/bitnami/postgresql/data/pg_wal 為 WAL 檔存放的資料夾
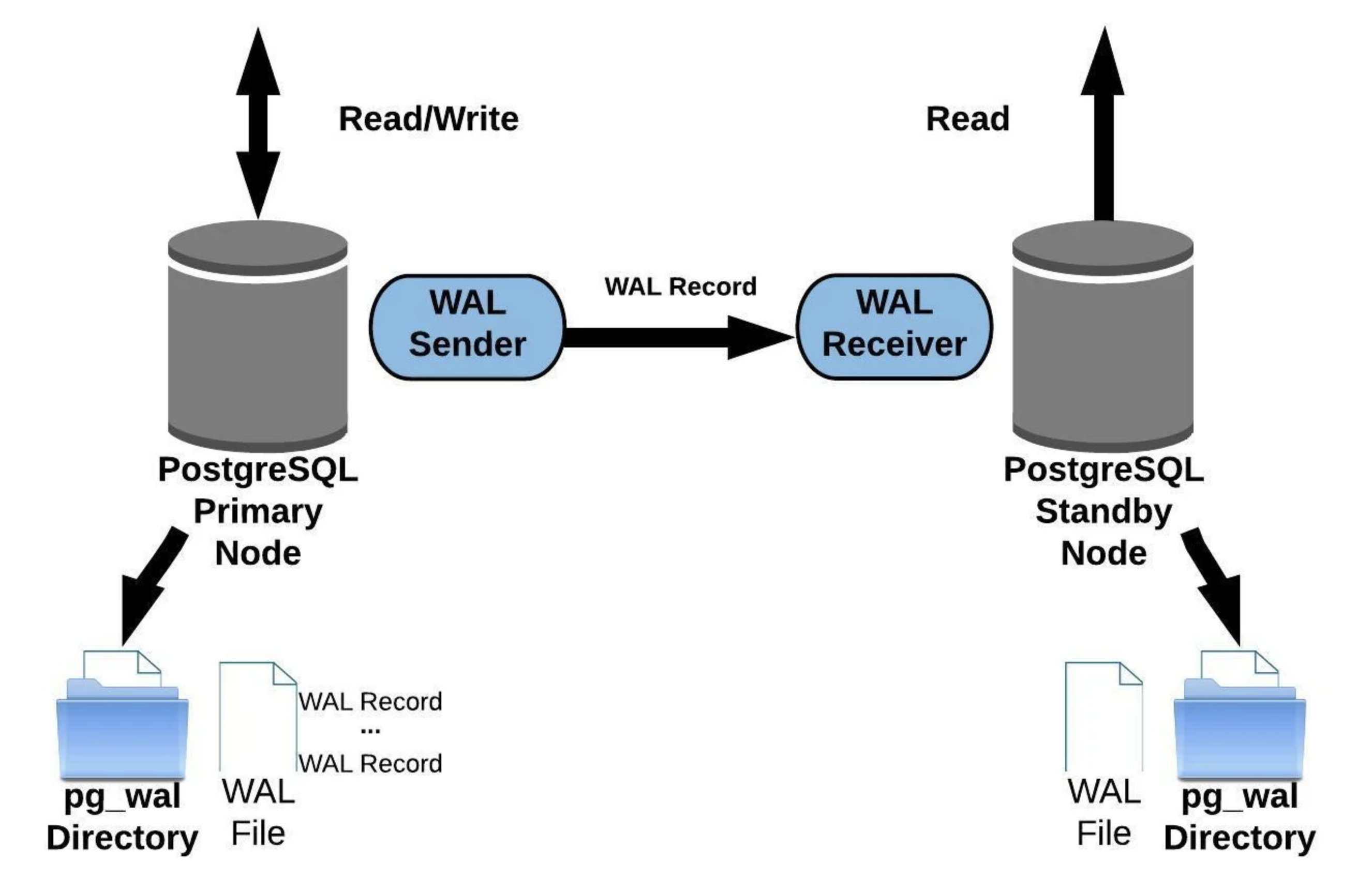
2. 分析問題 在實驗環境的 PostgreSQL master-slave 架構,是使用 Streaming Replication 的方式設定, 其資料同步如下圖
圖片來源:Postgres WAL Replication: Easy Step-By-Step Guide
根據 Monitoring PostgreSQL WAL Files 文章裡有一段提到,
Replication failures: When using streaming replication with replication slots, and a standby goes down, Postgres will retain the WAL files needed by the standby so that the standby can resume from the point where it left off. If the standby goes offline for extended periods of time, or if someone forgot to delete the replication slot on the primary, the WAL files can be retained indefinitely. Ensure all your standbys and replication slots are active, and that your standbys can keep up the the changes happening at the primary.
Stack overflow 的發文 Postgres, does streaming slave affect master health? 也提到相同的問題,
If you are using replication slots to retain WAL when the standby goes down, WAL will accumulate on the primary server and can fill up the disk, which will crash the primary server.
看來是踩到這個坑了。。。
檢查實驗設備的 master node,其 pg_wal 資料夾充滿了 WAL 檔,大概佔用了 3.7GB,而給 database 的磁碟空間只有 4GB,在磁碟空間被塞滿了的情況下,當然 database 就無法正常服務了。而 Slave node 的 container 則是不斷的重啟(註:一直到恢復 Master node 的 database 運作後,該 container 仍然無法正確啟動,只好強制刪除重建。)
2.1. Slave node 離線後 在模擬環境的 slave node VM,將 db container 停用,
1 $ docker stop SLAVE_NODE_DB
持續對 master node 寫入資料,發現 pg_wal 資料夾內的 WAL 檔不再自動 remove/recycle,而是一直增加 。
恢復 slave node db container,
1 $ docker start SLAVE_NODE_DB
Slave node 恢復後,master node 的 WAL 檔會減少到一定程度。
實驗結果:
當 Salve node 不斷的 UP/DOWN,並不會讓 WAL 檔無限增長,只要完成 replication,則 WAL 檔會減少到一定程度(略大於 max_wal_size 的設定)。
Salve node 離線後,一直未恢復,則 master node 的 WAL 檔就會不斷累積,直到磁碟空間用完。
看來實驗設備是 master node 一直無法與 slave node 正常連線(connection),所以才會讓 WAL 檔案不斷成長到塞爆磁碟空間。(爬 master node 的 syslog,確實沒看到 slave node 有回來(connection))
CAUTION:primary。
3. 處理 適用的情境,
預期 slave node 會長期離線
Slave node 已離線一段時間,master node 還可以正常服務
CAUTION
3.1. 縮減 pg_wal 佔用的空間 在模擬環境的 mater node VM 使用 docker exec 指令進入 db container,再登入 PostgreSQL,
1 $ PGPASSWORD=ADM_PSQL_PWD psql -U ADM_PSQL_ACCOUNT
ADM_PSQL_ACCOUNT 及 ADM_PSQL_PWD 為由權限操作 PostgreSQL 的帳號及密碼。
查詢 slave node db 在 replication slot 記錄的名稱,
1 SELECT * FROM pg_replication_slots;
結果如下,
1 2 3 4 slot_name | plugin | slot_type | datoid | database | temporary | active | active_pid | xmin | catalog_xmin | restart_lsn | confirmed_flush_lsn | wal_status | safe_wal_size ------------------+--------+-----------+--------+----------+-----------+--------+------------+------+--------------+-------------+---------------------+------------+--------------- repmgr_slot_1002 | | physical | | | f | f | 124985 | | | 0/3BC15070 | | reserved | (1 row)
只有一個 slave node - repmgr_slot_1002。欄位 active = f ,可以確定此 slot 未被用來執行 replication,同時也會造成 master node db 的 WAL 檔案持續增加。
刪除 slot,
1 SELECT pg_drop_replication_slot('repmgr_slot_1002' );
結果如下,
1 2 3 4 pg_drop_replication_slot -------------------------- (1 row)
為了讓 pg_wal 資料夾的佔用空間下降,可手動執行 checkpoint 或是等待系統自動的 checkpoint。
離開 PostgreSQL,可用 \q 或 exit。
3.1.1. 刪除 WAL files (optional) 如果 WAL 檔案仍然太多,可以在退出 PostgreSQL 後,在命令列執行 pg_archivecleanup 指令刪除已經 archive 的 WAL 檔。
進入 pg_wal 資料夾,
1 $ cd `/bitnami/postgresql/data/pg_wal`
查看 WAL 檔案完成 archive 的有哪些(副檔名有 .done 的才算完成),
1 2 3 4 5 6 7 8 $ ls -lh archive_status/ -rw------- 1 1001 root 0 Mar 24 08:15 00000001000000000000000F.done -rw------- 1 1001 root 0 Mar 24 08:17 000000010000000000000010.done -rw------- 1 1001 root 0 Mar 24 08:19 000000010000000000000011.done -rw------- 1 1001 root 0 Mar 24 08:21 000000010000000000000012.done -rw------- 1 1001 root 0 Mar 24 08:23 000000010000000000000013.done -rw------- 1 1001 root 0 Mar 24 08:25 000000010000000000000014.done
執行刪除已經 archive 的 WAL 檔,
1 2 3 4 5 6 $ pg_archivecleanup -d . 000000010000000000000014 pg_archivecleanup: keeping WAL file "./000000010000000000000014" and later pg_archivecleanup: removing file "./000000010000000000000013" pg_archivecleanup: removing file "./000000010000000000000012" ...
3.2. 將 slave node 加回來 在 slave node VM 命令列執行
1 $ docker restart DB_CONTAINER_NAME
Salve node db 加入並完成 replication,觀察 master node db 的 WAL 檔案,即刻會減少到一定程度,此後 master node db 的 pg_wal 的空間就不會再無限增長了,問題解決 :)
NOTICE
3.3. 檢查 replication state (optional) 再回到 master node 的 PostgreSQL 裡輸入,
1 SELECT * FROM pg_stat_replication;
結果如下,
1 2 3 4 5 pid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_start | backend_xmin | state | sent_lsn | write_lsn | flush_lsn | replay_lsn | write_lag | flush_lag | replay_lag | sync_priority | sync_state | reply_time --------+----------+---------+------------------+----------------+-----------------+-------------+-------------------------------+--------------+-----------+------------+------------+------------+------------+-----------------+-----------------+-----------------+---------------+------------+------------------------------- 124985 | 16385 | repmgr | irene_db-2 | 192.168.28.112 | | 52416 | 2023-03-24 09:26:19.384122+00 | | streaming | 0/41B27290 | 0/41B27290 | 0/41B27290 | 0/41B27290 | 00:00:00.000768 | 00:00:00.001562 | 00:00:00.003225 | 0 | async | 2023-03-24 09:49:35.682771+00 (1 row)
若 replay_lsn 的值未更新,就要檢查 slave node db 的狀態是否正常。
4. 觀察紀錄 補充一些實驗過程的紀錄。
4.1. 加入 Slave node Slave node db 加入後,會在 master node db 的 WAL 產生 .backup 檔案,以表示 repmgr 完成備份。
在 master node VM,進入 db container 的 /bitnami/postgresql/data/pg_wal folder,
1 2 3 4 5 6 7 8 9 10 11 12 $ ls -l -rw------- 1 1001 root 16777216 Mar 17 08:34 000000010000000000000005 -rw------- 1 1001 root 16777216 Mar 17 08:34 000000010000000000000006 -rw------- 1 1001 root 16777216 Mar 17 08:47 000000010000000000000007 -rw------- 1 1001 root 16777216 Mar 17 08:47 000000010000000000000008 -rw------- 1 1001 root 16777216 Mar 17 10:12 000000010000000000000009 -rw------- 1 1001 root 16777216 Mar 17 10:12 00000001000000000000000A -rw------- 1 1001 root 16777216 Mar 20 01:32 00000001000000000000000B -rw------- 1 1001 root 16777216 Mar 20 01:32 00000001000000000000000C -rw------- 1 1001 root 330 Mar 20 01:32 00000001000000000000000C.00000060.backup -rw------- 1 1001 root 16777216 Mar 20 01:37 00000001000000000000000D -rw------- 1 1001 root 16777216 Mar 17 03:15 00000001000000000000000E
00000001000000000000000B 檔案會即刻停止寫入,會產生 00000001000000000000000C 及 00000001000000000000000C.00000060.backup,並從 00000001000000000000000D 開始新的記錄。
使用 pg_waldump 可以查看 WAL 內容,
1 2 3 4 5 6 7 8 9 10 11 $ pg_waldump 00000001000000000000000B rmgr: Transaction len (rec/tot): 34/ 34, tx: 25661, lsn: 0/0B001370, prev 0/0B0012C8, desc: COMMIT 2023-03-17 10:12:12.351299 UTC rmgr: Standby len (rec/tot): 50/ 50, tx: 0, lsn: 0/0B001398, prev 0/0B001370, desc: RUNNING_XACTS nextXid 25662 latestCompletedXid 25661 oldestRunningXid 25662 rmgr: Standby len (rec/tot): 50/ 50, tx: 0, lsn: 0/0B0013D0, prev 0/0B001398, desc: RUNNING_XACTS nextXid 25662 latestCompletedXid 25661 oldestRunningXid 25662 rmgr: XLOG len (rec/tot): 114/ 114, tx: 0, lsn: 0/0B001408, prev 0/0B0013D0, desc: CHECKPOINT_ONLINE redo 0/B0013D0; tli 1; prev tli 1; fpw true ; xid 0:25662; oid 24646; multi 1; offset 0; oldest xid 478 in DB 1; oldest multi 1 in DB 1; oldest/newest commit timestamp xid: 0/0; oldest running xid 25662; online rmgr: Standby len (rec/tot): 50/ 50, tx: 0, lsn: 0/0B001480, prev 0/0B001408, desc: RUNNING_XACTS nextXid 25662 latestCompletedXid 25661 oldestRunningXid 25662 rmgr: XLOG len (rec/tot): 114/ 114, tx: 0, lsn: 0/0B0014B8, prev 0/0B001480, desc: CHECKPOINT_SHUTDOWN redo 0/B0014B8; tli 1; prev tli 1; fpw true ; xid 0:25662; oid 24646; multi 1; offset 0; oldest xid 478 in DB 1; oldest multi 1 in DB 1; oldest/newest commit timestamp xid: 0/0; oldest running xid 0; shutdown rmgr: Heap len (rec/tot): 54/ 3214, tx: 25662, lsn: 0/0B001530, prev 0/0B0014B8, desc: INSERT off 26 flags 0x00, blkref rmgr: Transaction len (rec/tot): 34/ 34, tx: 25662, lsn: 0/0B0021D8, prev 0/0B001530, desc: COMMIT 2023-03-20 01:30:54.817248 UTC rmgr: Standby len (rec/tot): 50/ 50, tx: 0, lsn: 0/0B002200, prev 0/0B0021D8, desc: RUNNING_XACTS nextXid 25663 latestCompletedXid 25662 oldestRunningXid 25663 rmgr: XLOG len (rec/tot): 24/ 24, tx: 0, lsn: 0/0B002238, prev 0/0B002200, desc: SWITCH
.backup 檔案可以用 cat 命令,
1 2 3 4 5 6 7 8 9 10 11 $ cat 00000001000000000000000C.00000060.backup START WAL LOCATION: 0/C000060 (file 00000001000000000000000C) STOP WAL LOCATION: 0/C000138 (file 00000001000000000000000C) CHECKPOINT LOCATION: 0/C000098 BACKUP METHOD: streamed BACKUP FROM: master START TIME: 2023-03-20 01:32:31 GMT LABEL: repmgr base backup START TIMELINE: 1 STOP TIME: 2023-03-20 01:32:32 GMT STOP TIMELINE: 1
CHECKPOINT LOCATION: 0/C000098
LABEL: repmgr base backup
在 slave node VM,進入 db container 的 /bitnami/postgresql/data/pg_wal folder,
1 2 3 4 5 $ ls -lh total 32772 -rw------- 1 1001 root 16777216 Mar 20 01:32 00000001000000000000000C -rw------- 1 1001 root 16777216 Mar 20 01:37 00000001000000000000000D drwx------ 2 1001 root 4096 Mar 20 01:32 archive_status
使用 pg_waldump 可以查看 WAL 內容,
1 2 3 4 5 6 $ pg_waldump 00000001000000000000000C rmgr: Standby len (rec/tot): 50/ 50, tx: 0, lsn: 0/0C000028, prev 0/0B002238, desc: RUNNING_XACTS nextXid 25663 latestCompletedXid 25662 oldestRunningXid 25663 rmgr: Standby len (rec/tot): 50/ 50, tx: 0, lsn: 0/0C000060, prev 0/0C000028, desc: RUNNING_XACTS nextXid 25663 latestCompletedXid 25662 oldestRunningXid 25663 rmgr: XLOG len (rec/tot): 114/ 114, tx: 0, lsn: 0/0C000098, prev 0/0C000060, desc: CHECKPOINT_ONLINE redo 0/C000060; tli 1; prev tli 1; fpw true ; xid 0:25663; oid 24646; multi 1; offset 0; oldest xid 478 in DB 1; oldest multi 1 in DB 1; oldest/newest commit timestamp xid: 0/0; oldest running xid 25663; online rmgr: XLOG len (rec/tot): 34/ 34, tx: 0, lsn: 0/0C000110, prev 0/0C000098, desc: BACKUP_END 0/C000060 rmgr: XLOG len (rec/tot): 24/ 24, tx: 0, lsn: 0/0C000138, prev 0/0C000110, desc: SWITCH
4.2. 舊檔再利用 當 master node db 裡的 WAL 增加到指超過 max_wal_size 許多後,slave node db 才加入(或恢復),雖然 WAL 檔案會減少到一定程度(略大於 max_wal_size),不過可以發現舊的 WAL 檔案會被重新命名再利用。而再利用的舊檔,並不一定是依據檔案建立的時間順序拿來使用。
在 master node VM 進入 db container 後執行,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 $ ls -lh /bitnami/postgresql/data/pg_wal total 209M -rw------- 1 1001 root 333 Mar 22 02:06 000000010000000000000011.00000028.backup -rw------- 1 1001 root 16M Mar 22 02:22 000000010000000000000016 -rw------- 1 1001 root 16M Mar 22 02:26 000000010000000000000017 -rw------- 1 1001 root 16M Mar 22 02:29 000000010000000000000018 -rw------- 1 1001 root 16M Mar 22 02:32 000000010000000000000019 -rw------- 1 1001 root 16M Mar 22 02:36 00000001000000000000001A -rw------- 1 1001 root 16M Mar 22 02:39 00000001000000000000001B -rw------- 1 1001 root 16M Mar 22 02:42 00000001000000000000001C -rw------- 1 1001 root 16M Mar 22 02:46 00000001000000000000001D -rw------- 1 1001 root 16M Mar 22 02:48 00000001000000000000001E -rw------- 1 1001 root 16M Mar 22 02:06 00000001000000000000001F -rw------- 1 1001 root 16M Mar 22 02:13 000000010000000000000020 -rw------- 1 1001 root 16M Mar 22 02:19 000000010000000000000021 -rw------- 1 1001 root 16M Mar 22 02:16 000000010000000000000022
再利用的舊檔,
1 2 3 4 -rw------- 1 1001 root 16M Mar 22 02:06 00000001000000000000001F -rw------- 1 1001 root 16M Mar 22 02:13 000000010000000000000020 -rw------- 1 1001 root 16M Mar 22 02:19 000000010000000000000021 -rw------- 1 1001 root 16M Mar 22 02:16 000000010000000000000022
000000010000000000000022 的建立時間比 000000010000000000000021 早,但比後者晚被重新命名。
4.3. If the slave’s replay is paused 實驗結果:
Slave node database 內的資料會暫停更新
Master node db 會持續將異動資料傳送給 slave node db,以寫入 slave node db 的 WAL (持續增加檔案)
在 slave node 的 PostgreSQL 裡輸入,
1 SELECT pg_is_in_recovery();
結果如下,
1 2 3 4 pg_is_in_recovery ------------------- t (1 row)
若回傳值為 t 則表示 salve node 是在 recovery mode。
執行 pause 命令,
1 SELECT pg_wal_replay_pause();
再檢查 replay 狀態,
1 SELECT pg_is_wal_replay_paused();
回傳值為 t 表示 recovery process 被暫停了(paused)。這將會讓 slave node db 的資料暫停更新,同時 slave node 的 pg_wal 會持續增加 WAL 檔案,一直到恢復 recovery process。
執行 resume 命令,
1 SELECT pg_wal_replay_resume();
再檢查 replay 狀態,
1 SELECT pg_is_wal_replay_paused();
回傳值為 f 表示 recovery process 已經恢復,此時 db 的資料會更新,同時消化掉 pg_wal 內的 WAL 檔案,可以觀察到 pg_wal 佔用空間小於 max_wal_size,會略大於 wal_keep_size。
5. References